|
Dr. Xiaocheng Tang is an AI Research Scientist at Meta Superintelligence Labs (MSL), where he works on efficient reasoning, agentic reinforcement learning beyond GRPO, and self-improvement for frontier large language models (the Llama series). His work to date has made reinforcement learning work reliably at the frontier — across stable multi-turn and rubric-based multi-domain RL, reward modeling, efficient knowledge distillation, and cold-start test-time scaling — research that shaped the post-training of Llama 4 and Llama 3 and produced LlamaRL, a distributed asynchronous RL framework for large-scale training. He is now focused on what reliable and efficient RL makes possible: agentic systems that conduct scientific and AI research on their own — proposing and running their own experiments. The self-improvement he cares about is sample-efficient and generalizable — recursive self-improvement driven by diversity, agency, and open-ended search under constraints rather than brute-force scale, discovering meta-learning rules and objectives that transfer to tasks never seen in training. More broadly, he works at the intersection of reinforcement learning, large-scale optimization, and learning systems. Previously, he was a Senior Staff Research Scientist and engineering manager at DiDi AI Labs, where he pioneered novel reinforcement learning modeling to build self-reinforced agent at scale — from driver-passenger matching in the ride-hailing marketplace to motion planning and prediction for autonomous driving — and published 30+ conference, journal, and patent papers. His work on joint order dispatching and repositioning via RL received the Daniel H. Wagner Prize for Excellence in Operations Research at INFORMS 2019 and Best Demo Awards at NeurIPS 2018. His work on AutoML in collaboration with UCLA won an Outstanding Paper Award at ICLR 2021 (code), and his golfer model ranked 1st by minADE in the 2022 Waymo Open Dataset Motion Prediction Challenge. Xiaocheng received his PhD degrees in Optimization and Machine Learning advised by Prof. Katya Scheinberg (wiki). During his graduate study, he has been actively engaged in analyzing and designing novel optimization theories and algorithms for large-scale problems arising from various applications and in particular those in Artificial Intelligence. His work in fast and scalable training algorithms and convergence theory was presented at NIPS 2013 and was published in the journal of Mathematical Programming which is ranked the No.1 journal in the field of Mathematical Optimization by Google Scholar. Xiaocheng is also an Apache Committer contributing to Apache MADlib — a distributed in-database machine learning library started by Chris Ré from Stanford and Joe Hellerstein from Berkeley among others. He used to work in Numerical Methods group in IBM T.J. Watson Research, Yorktown Heights, NY, and was funded by Yahoo FREP award working on online AD targeting and user personalization in Machine Learning group in Yahoo Labs, Sunnyvale, CA in 2014. He earned his undergrad degree with High Honors from Chu KoChen Honors College and College of Control Science and Engineering in Zhejiang University, Hangzhou, China . Email / GitHub / Google Scholar / LinkedIn |

|
News
|
ResearchI'm interested in reasoning, agentic RL, and multi-agent applications for large language models — efficient test-time compute and multi-turn reasoning, reward modeling and reward engineering, self-play with co-evolving verifiers, and on-policy distillation for dense per-token supervision — together with the large-scale optimization and distributed systems that make frontier-model training efficient. Representative papers are highlighted. |
|
Algorithm Aversion: Evidence from Ridesharing DriversMeng Liu (WUSTL), Xiaocheng Tang, Siyuan Xia (SJTU), Shuo Zhang (SJTU), Yuting Zhu (NUS), and Qianying Meng Management Science 72(1):193-203, 2026 AI algorithms often cannot realize their intended efficiency gains because of their low adoption by human users. We uncover various factors that explain ridesharing drivers’ aversion to an algorithm designed to help them make better location choices. We discuss the managerial implications of these findings. Published in Management Science. |

|
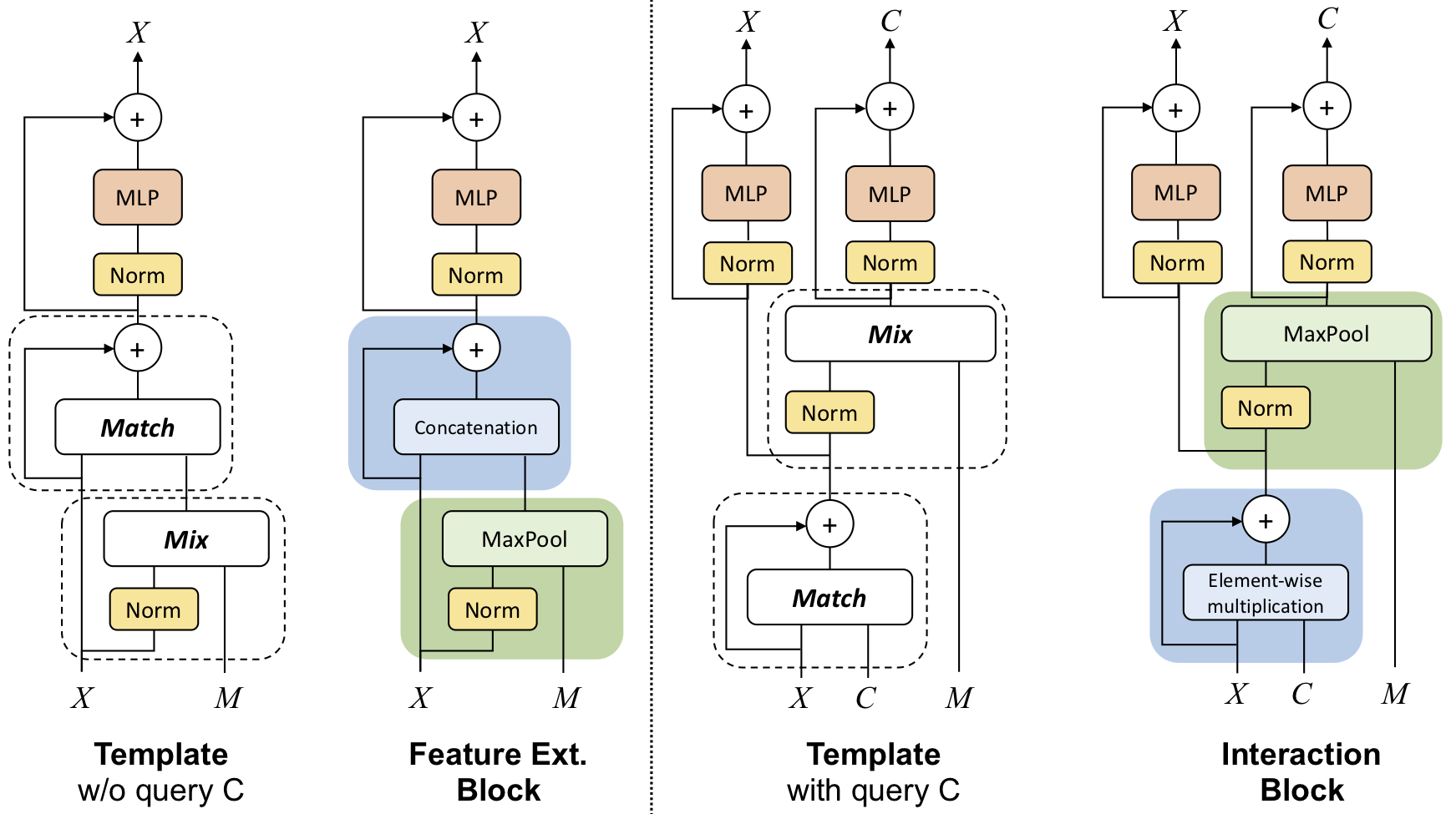
Beyond Reasoning Gains: Mitigating General Capabilities Forgetting in Large Reasoning ModelsHoang Phan, Xianjun Yang, Kevin Yao, Jingyu Zhang, Shengjie Bi, Xiaocheng Tang, Madian Khabsa, Lijuan Liu, Deren Lei arXiv preprint, Meta, 2025 arxiv / Reinforcement learning with verifiable rewards (RLVR) sharpens reasoning, but prolonged post-training can quietly erode foundational skills such as perception and faithfulness — and a task-local KL penalty, computed only on the current objective, does not guard the broader knowledge. This paper introduces RECAP, an experience-replay strategy with dynamic objective reweighting that adapts online from short-horizon signals of convergence and instability, shifting focus away from saturated objectives and toward underperforming or volatile ones. It is end-to-end and drops into existing RLVR pipelines with no auxiliary models or heavy tuning; on Qwen2.5-VL-3B and Qwen2.5-VL-7B it preserves general capabilities while improving reasoning through more flexible reward trade-offs. |

|
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM TrainingBo Wu, Sid Wang, Yunhao Tang, Jia Ding, Eryk Helenowski, Liang Tan, Tengyu Xu, Tushar Gowda, Zhengxing Chen, Chen Zhu, Xiaocheng Tang, Yundi Qian, Beibei Zhu, Rui Hou arXiv preprint, Meta, 2025 arxiv / A fully distributed, asynchronous reinforcement learning framework for post-training large language models at scale, built entirely on native PyTorch with a single-controller design that scales from a handful to thousands of H100 GPUs. LlamaRL combines co-located model offloading, asynchronous off-policy training, and distributed direct-memory weight synchronization, with a formal proof that the asynchronous design yields a strict speed-up — up to 10.7x over DeepSpeed-Chat-style systems on a 405B-parameter policy. |

|
The Llama 4 Herd: Natively Multimodal IntelligenceLlama Team, AI @ Meta (incl. Xiaocheng Tang) Meta AI, 2025 The Llama 4 herd — a family of natively multimodal mixture-of-experts models, including Llama 4 Scout (17B active / 16 experts, 10M-token context) and Llama 4 Maverick (17B active / 128 experts), distilled from the Llama 4 Behemoth teacher. I contributed to the reinforcement learning post-training behind the release. See the official announcement for model details and benchmarks. |
|
Spatio-Temporal Prediction of Fine-Grained Origin-Destination Matrices with Applications in RidesharingRun Yang, Runpeng Dai, Siran Gao, Xiaocheng Tang, Fan Zhou, Hongtu Zhu Journal of Computational and Graphical Statistics, 2025 arxiv / Accurate spatio-temporal prediction of origin-destination (OD) demand lets ridesharing platforms pre-position supply and rebalance idle drivers ahead of demand. This work targets fine-grained OD prediction over a large set of small regions, where the OD matrix is extremely sparse (exceeding 90%). The proposed OD-CED model pairs an unsupervised space-coarsening step that alleviates sparsity with an encoder-decoder that captures both semantic and geographic dependencies, reducing root-mean-square error by up to 45% and weighted mean absolute percentage error by up to 60% over traditional statistical baselines. Published in the Journal of Computational and Graphical Statistics. |

|
Reinforcement Learning in the Ridesharing MarketplaceZhiwei (Tony) Qin, Xiaocheng Tang, Qingyang Li, Hongtu Zhu, Jieping Ye Synthesis Lectures on Learning, Networks, and Algorithms, Springer, 2024 A graduate-level monograph offering a comprehensive treatment of reinforcement learning for ridesharing optimization — order dispatching, driver repositioning, and dynamic pricing — together with the closely related methods of approximate dynamic programming and model-predictive control. Published in Springer’s Synthesis Lectures on Learning, Networks, and Algorithms series (Springer). |

|
The Llama 3 Herd of ModelsLlama Team, AI @ Meta (incl. Xiaocheng Tang) Meta AI, 2024 arxiv / A herd of foundation models that natively support multilinguality, coding, reasoning, and tool use, with a flagship 405B-parameter dense model and a 128K-token context window. The report details the full pre- and post-training recipe — supervised fine-tuning, reward modeling, rejection sampling, and RLHF — that underlies the released Llama 3.1 models, alongside extensive empirical evaluation against frontier systems. |
|
Golfer: Trajectory Prediction with Masked Goal Conditioning MnM NetworkXiaocheng Tang, Soheil Sadeghi Eshkevari, Haoyu Chen, Weidan Wu, Wei Qian, Xiaoming Wang Waymo Open Dataset Challenge Winner, CVPR Workshop on Autonomous Driving, 2022 arxiv / Transformers have enabled breakthroughs in NLP and computer vision, and have recently began to show promising performance in trajectory prediction for Autonomous Vehicle (AV). However, efficiently modeling the interactive relationships between the ego agent and other road and dynamic objects remains challenging for the standard attention module. In this work we propose a general Transformer-like architectural module MnM network equipped with novel masked goal conditioning training procedures for AV trajectory prediction. The resulted model, named golfer, achieves state-of-the-art performance, winning the 2nd place in the 2022 Waymo Open Dataset Motion Prediction Challenge and ranked 1st place according to minADE. |
|
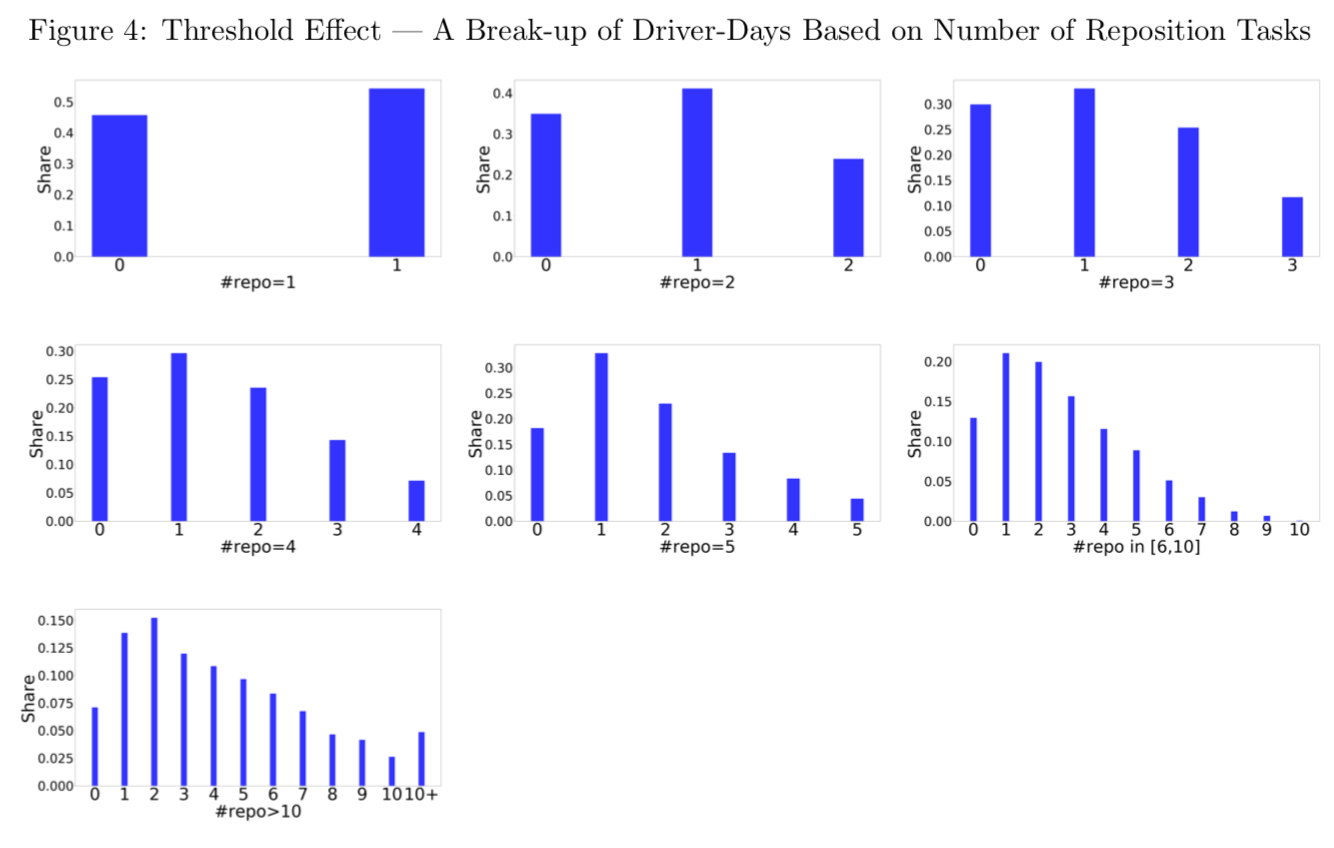
Reinforcement Learning in the Wild: Scalable RL Dispatching Algorithm Deployed in Ridehailing MarketplaceSoheil Sadeghi Eshkevari, Xiaocheng Tang, Zhiwei Tony Qin, Jinhan Mei, Cheng Zhang, Qianying Meng, Jia Xu ACM/SIGKDD, 2022 arxiv / The latest work of our sequel (part I and II) on RL-based dispatching algorithm for the ridehailing industry. The algorithm was proposed to particularly account for the human aspect of the problem, e.g., Human-Centered AI, and was deployed in a major international city to interact each day with hundreds of thousand drivers and passenger requests, in which we find that a feedback mechanism based on the contrastive style learning and long-term value bootstrapping can be especially beneficial to improve the marketplace efficiency. |
|
|
RANK-NOSH: Efficient Predictor-Based Architecture Search via Non-Uniform Successive HalvingRuochen Wang, Xiangning Chen, Minhao Cheng, Xiaocheng Tang, Cho-Jui Hsieh ICCV, 2021 arxiv / We propose NOn-uniform Successive Halving (NOSH), a hierarchical scheduling algorithm, combined within a GNN-based learning to rank with pairwise comparisons formulation for predictor-based architecture search. The resulting method - RANK-NOSH, reduces the search budget by ~5x while achieving competitive or even better performance than previous state-of-the-art predictor-based methods on various spaces and datasets. |

|
Measuring Sample Efficiency and Generalization in Reinforcement Learning Benchmarks: NeurIPS 2020 Procgen BenchmarkSharada Mohanty, Jyotish Poonganam, Adrien Gaidon, Andrey Kolobov, Blake Wulfe, Dipam Chakraborty, Gražvydas Šemetulskis, João Schapke, Jonas Kubilius, Jurgis Pašukonis, Linas Klimas, Matthew Hausknecht, Patrick MacAlpine, Quang Nhat Tran, Thomas Tumiel, Xiaocheng Tang, Xinwei Chen, Christopher Hesse, Jacob Hilton, William Hebgen Guss, Sahika Genc, John Schulman, Karl Cobbe Proceedings of the NeurIPS 2020 Competition and Demonstration Track, PMLR 133:361-395, 2021 arxiv / video / The NeurIPS 2020 Procgen Competition by OpenAI was designed as a centralized benchmark with clearly defined tasks for measuring Sample Efficiency and Generalization in Reinforcement Learning. This paper presents the competition setup and the details and analysis of the top solutions identified through this setup in context of 2020 iteration of the competition at NeurIPS. |
|
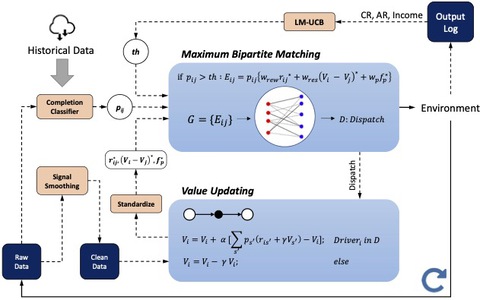
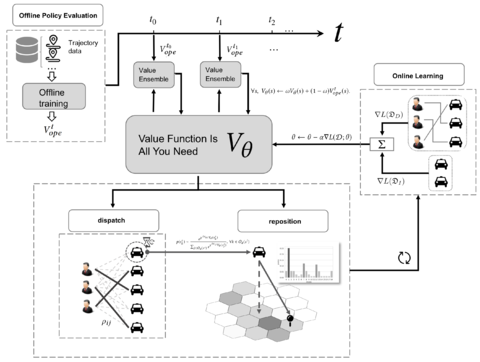
Value Function is All You Need: A Unified Learning Framework for Ride Hailing PlatformsXiaocheng Tang, Fan Zhang, Zhiwei Tony Qin, Yansheng Wang, Dingyuan Shi, Bingchen Song, Yongxin Tong, Hongtu Zhu, Jieping Ye Oral presentation, ACM/SIGKDD, 2021 arxiv / video / slides / We propose a unified value-based dynamic learning framework (V1D3) for tackling both order dispatching and vehicle repositioning. At the center of the framework is a globally shared value function that is updated continuously using online experiences generated from real-time platform transactions. V1D3 outperforms the first prize winners of both dispatching and repositioning tracks in the KDD Cup 2020 RL competition, achieving state-of-the-art results on improving both total driver income and user experience related metrics. |
|
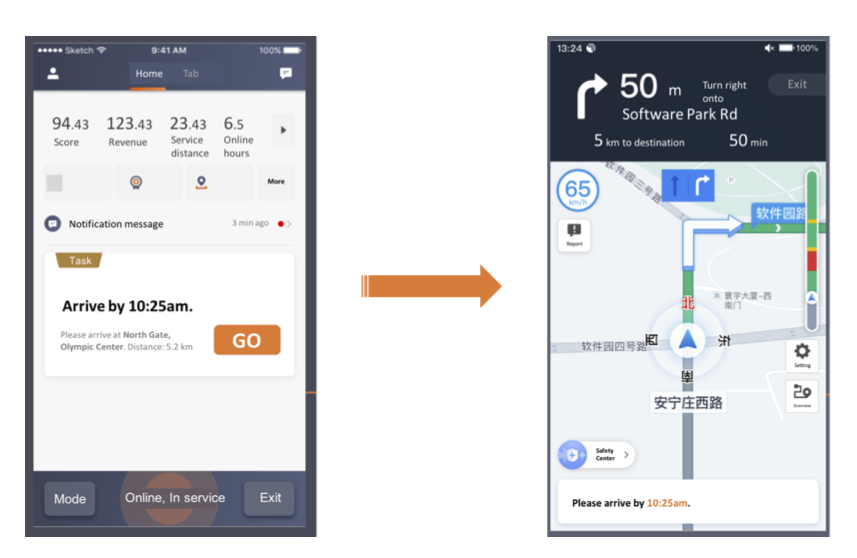
Real-world Ride-hailing Vehicle Repositioning using Deep Reinforcement LearningYan Jiao, Xiaocheng Tang, Zhiwei Tony Qin, Shuaiji Li, Fan Zhang, Hongtu Zhu, Jieping Ye Transportation Research Part C: Emerging Technologies, 2021 arxiv / We present a new practical framework based on deep reinforcement learning and decision-time planning for real-world vehicle repositioning on ride-hailing (a type of mobility-on-demand, MoD) platforms. We have also designed and run a real-world experiment program with regular drivers on a major ride-hailing platform. We have observed significantly positive results on key metrics comparing our method with experienced drivers who performed idle-time repositioning based on their own expertise. |
|
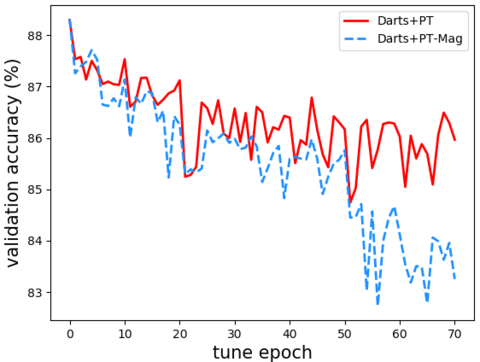
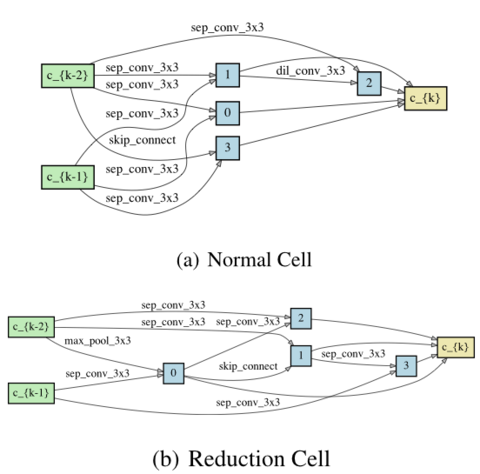
Rethinking Architecture Selection in Differentiable NASRuochen Wang, Minhao Cheng, Xiangning Chen, Xiaocheng Tang, Cho-Jui Hsieh Outstanding Paper Awards, 8 out of 860 accepted papers, ICLR, 2021 arxiv / code / We provide empirical and theoretical analysis on the magnitude of architecture parameters and find that several failure modes of Darts can be greatly alleviated with the proposed perturbation-based method, indicating that much of the poor generalization observed in Darts can be attributed to the failure of magnitude-based architecture selection rather than entirely the optimization of its supernet. |
|
DrNAS: Dirichlet Neural Architecture SearchXiangning Chen, Ruochen Wang, Minhao Cheng, Xiaocheng Tang, Cho-Jui Hsieh ICLR, 2021 arxiv / code / This paper proposes a novel differentiable architecture search method by formulating it into a distribution learning problem. We treat the continuously relaxed architecture mixing weight as random variables, modeled by Dirichlet distribution. We obtain a test error of 2.46% for CIFAR-10, 23.7% for ImageNet under the mobile setting. |

|
KDDCUP 2020: Learning to Dispatch and Reposition on a Mobility-on-Demand PlatformZhiwei Qin, Xiaocheng Tang, Lulu Zhang, Yanhui Ma, Jianhua Zhang, Fan Zhang, Cheng Zhang ACM/SIGKDD, 2020 video / code / The challenge that the participants are to solve involves a combination of order dispatching (order matching) and vehicle repositioning (fleet management) on an MoD platform. The teams are to develop algorithms for either or both of these tasks. The algorithms are evaluated in a simulation environment that simulates the dynamics of an MoD platform. |

|
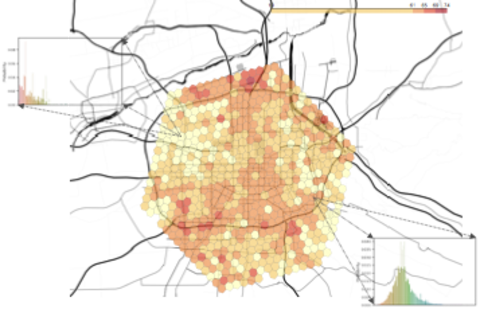
Wagner Prize Winner: Ride-hailing Order Dispatching on DiDi via Reinforcement LearningZhiwei Qin, Xiaocheng Tang, Yan Jiao, Fan Zhang, Zhe Xu, Hongtu Zhu, Jieping Ye INFORMS/Daniel H. Wagner prize for Excellence in Operations Research, 2019 arxiv / video / slides / The evolution of our approach to the optimization problem of order dispatching from a myopic combinatorial optimization approach to one that encompasses a semi-MDP model and deep reinforcement learning for long-term optimization. |
|
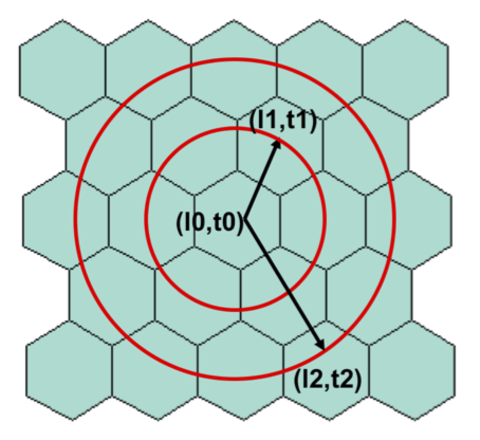
A Deep Value-network Based Approach for Multi-Driver Order DispatchingXiaocheng Tang, Zhiwei Tony Qin, Fan Zhang, Zhaodong Wang, Zhe Xu, Yintai Ma, Hongtu Zhu, Jieping Ye Oral presentation, acceptance rate 6%, ACM/SIGKDD, 2019 arxiv / video / slides / We propose a deep reinforcement learning based solution for order dispatching and we conduct large scale online A/B tests on DiDi’s ride-dispatching platform to show that the proposed method achieves significant improvement on both total driver income and user experience related metrics. |
|
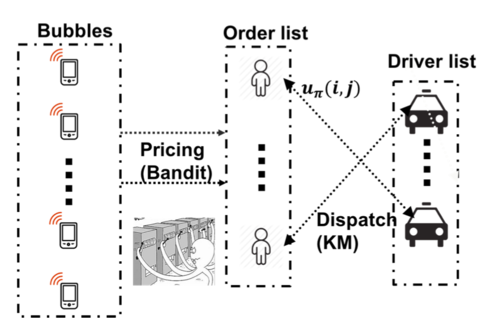
InBEDE: Integrating Contextual Bandit with TD Learning for Joint Pricing and Dispatch of Ride-Hailing PlatformsHaipeng Chen, Yan Jiao, Zhiwei Tony Qin,Xiaocheng Tang, Hao Li, Bo An, Hongtu Zhu, Jieping Ye IEEE/International Conference on Data Mining (ICDM), 2019 arxiv / Classic approaches to improve marketplace efficiency usually optimize pricing or dispatch separately. We show that these two processes are in fact intrinsically interrelated, and motivated by this observation, we make an attempt to simultaneously optimize pricing and dispatch strategies. |
|
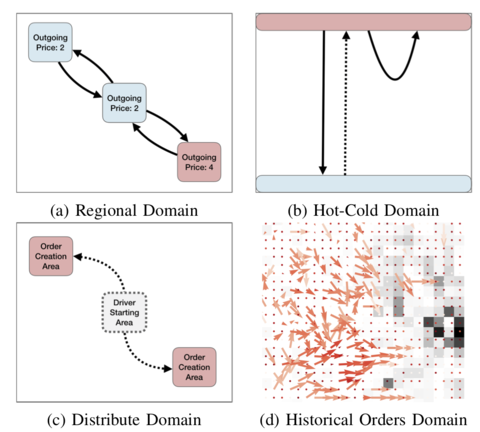
Deep Reinforcement Learning for Dynamic Multi-Driver Dispatching and Repositioning ProblemJohn Holler, Risto Vuorio, Zhiwei Qin, Xiaocheng Tang, Yan Jiao, Tiancheng Jin, Satinder Singh, Chenxi Wang, and Jieping Ye IEEE/International Conference on Data Mining (ICDM), 2019 arxiv / We present a deep reinforcement learning approach for tackling the full fleet management and dispatching problems. In addition to treating the drivers as individual agents, we consider the problem from a system-centric perspective, where a central fleet management agent is responsible for decision-making for all drivers. |
|
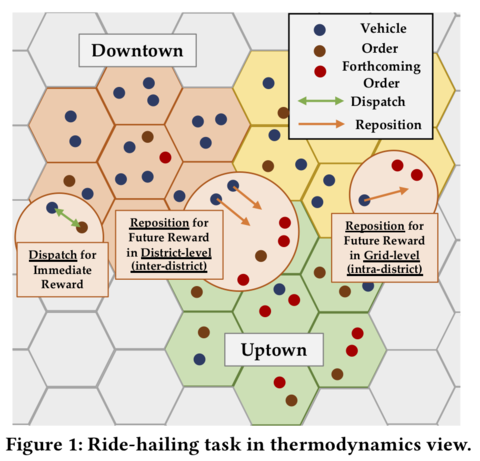
CoRide: Joint Order Dispatching and Fleet Management for Multi-Scale Ride-Hailing PlatformsJiarui Jin, Ming Zhou, Weinan Zhang, Minne Li, Zilong Guo, Zhiwei Qin, Yan Jiao, Xiaocheng Tang, Chenxi Wang, Jun Wang, Guobin Wu, Jieping Ye ACM/International Conference on Information and Knowledge Management (CIKM), 2019 arxiv / We model ride-hailing as a large-scale parallel ranking problem and study the joint decision-making task of order dispatching and fleet management. We leverage the geographical hierarchy of the region grids to perform hierarchical reinforcement learning. And to deal with the heterogeneous and variant action space for joint order dispatching and fleet management, we design the action as the ranking weight vector to rank and select the specific order or the fleet management destination in a unified formulation. |
|
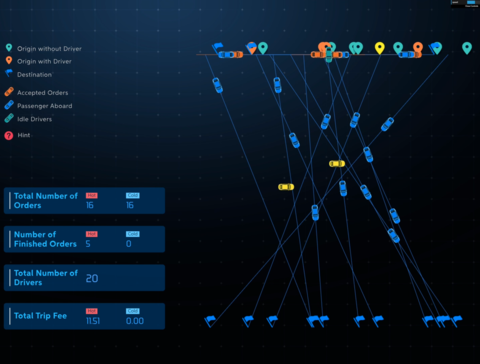
NeurIPS Best Demo Awards: Deep RL for Online Order Dispatching and Driver RepositioningXiaocheng Tang, Zhiwei Qin, Yan Jiao, Jieping Ye, Chenxi Wang NeurIPS, 2018 video / An end-to-end attention-based learning system to demonstrate the joint training of dispatching and repositioning that is capable of adaptively optimizing the distribution alignment between orders and drivers in a manner that maximizes the total income for the drivers. |
|
Deep Reinforcement Learning with Knowledge Transfer for Online Rides Order DispatchingZhaodong Wang*, Zhiwei Qin*, Xiaocheng Tang*, Jieping Ye, Hongtu Zhu IEEE/International Conference on Data Mining (ICDM), 2018 arxiv / Ride dispatching is a central operation task on a ride-sharing platform to continuously match drivers to trip-requesting passengers. We propose learning solutions based on deep Q-networks with action search to optimize the dispatching policy for drivers on ride-sharing platforms. We train and evaluate dispatching agents for this challenging decision task using real-world spatio-temporal trip data from the DiDi ride-sharing platform. |
|
Practical inexact proximal quasi-Newton method with global complexity analysisKatya Scheinberg, Xiaocheng Tang Mathematical Programming A, 2016 arxiv / video / code / slides / Recently several methods were proposed for sparse optimization which make careful use of second-order information to improve local convergence rates. We propose a general framework, which includes slightly modified versions of existing algorithms and also a new algorithm, which uses limited memory BFGS Hessian approximations, and provide a novel global convergence rate analysis, which covers methods that solve subproblems via coordinate descent. |
|
A Fast Decomposition Approach for Traffic ControlXiaocheng Tang,Sebastien Blandin, Laura Wynter International Federation of Automatic Control, 2014 arxiv / We present a fast decomposition method for network optimization problems, with application to real-time traffic control. Our approach is based on a nonlinear programming formulation of the network control problem and consists of an alternating directions method using forward numerical simulation inplace of one of the optimization subproblems. The method is scalable to realistic city-size road networks for real-time applications, and is shown to perform well on synthetic and real traffic networks. |
|
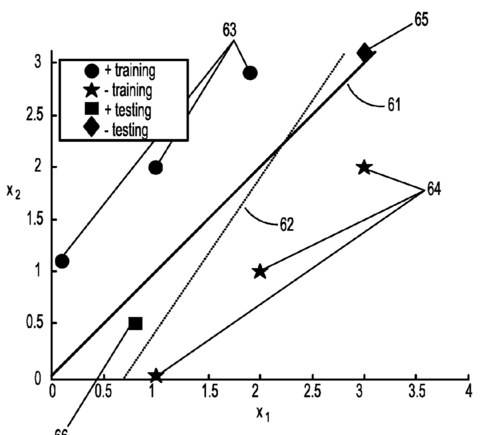
HIPAD-A Hybrid Interior-Point Alternating Direction algorithm for knowledge-based SVM and feature selectionZhiwei Qin, Xiaocheng Tang, Ioannis Akrotirianakis, Amit Chakraborty International Conference on Learning and Intelligent Optimization, 2014 arxiv / We propose a new hybrid optimization algorithm that solves the elastic-net support vector machine (SVM) through an alternating direction method of multipliers in the first phase, followed by an interior-point method for the classical SVM in the second phase. Both SVM formulations are adapted to knowledge incorporation. Our proposed algorithm addresses the challenges of automatic feature selection, high optimization accuracy, and algorithmic flexibility for taking advantage of prior knowledge. |
|
|